17 December 2022
A couple of weeks ago I migrated a React project using redux to Redux Toolkit.
Redux has always been my preferred state management tool for React (which doesn’t mean I “love” it), but one of its main problems is the amount of boilerplate code it requires.
Because of that I had a couple of helper functions, but there was still some things not properly handled, like proper type inference on reducers and actions (I use TypeScript).
A bit by accident (I think it was on Twitter), I found out about Redux Toolkit (RTK from now on), an official library from the redux team, which provides some opinionated helpers to reduce the amount of boilerplate, and I decided to give it a chance.
These are my impressions.
TL;DR
I first started to use it in a proof of concept, and I quickly loved it.
RTK does not “replace” any of the redux principles, so you can progressively adopt it, by replacing small bits of code. My plan was to use it just for some reducers, but I liked it so much that I ended up migrating the whole project in a series of consecutive pull requests.
A bit of context
Before the migration, I used to follow the ducks modular pattern, which promotes putting all your action types, action creators and the reducer handling those actions on the same module.
This fits pretty well with RTK, as in most of the cases you will use slices, and end up exporting the reducer and action creators returned by it, from the same module.
If you use async thunks, they usually need to be used by that same slice, so it’s not a bad idea to export them also from there.
Why I love it
There are a couple of reasons for which I loved RTK right away. The main one is that they make an impressive work on making type inference in TypeScript work properly.
- Slices detect the type of the initial state in order to know what is expected to be passed as
stateto reducers. - You can infer the type of your store from what is generated by
configureStoreorcombineReducersfunctions, allowing you to also properly type thedispatchfunction. - Action creators are generated with the proper param types based on the reducers provided to
createSliceor the callback provided tocreateAsyncThunk. createSlicecan consume all the action creators generated bycreateAsyncThunk, and infer the proper payload for each one of them.
Thanks to this, the code is super predictable and potential bugs can be caught sooner.
More details on how to use RTK with typescript https://redux-toolkit.js.org/usage/usage-with-typescript
But this is not the only benefit. Other reasons that make it very nice to work with are:
- It keeps the same concepts from Redux, but removing the boilerplate or your own helper functions if you have them (yes, I didn’t want to keep all those
switchstatements everywhere). - It is mostly transparent for the components dispatching the actions or consuming the state.
- All the tests covering your reducers/actions/components should keep passing, as the outcome from RTK is the same as if you built everything manually.
- It introduces a couple of extra helpers, like RTK query or the listener middleware, which is very useful to dispatch actions as a result of other actions being dispatched.
Challenges I found
Of course, adopting a new tool always comes with some challenges.
The main “problem” I found is that RTK is a bit opinionated, but that’s precisely how they manage to reduce boilerplate code, and it’s also “advertised” in their website, so not a big surprise.
I usually prefer to be in control of everything (configuration over convention), but that’s just a personal preference, and sometimes it’s ok to accept a bit of magic for the sake of simplicity.
This caused the next challenges for my particular case:
-
RTK assumes your project follows a strict Flux pattern, meaning your actions always have the properties
type,payloadand optionallymetaanderror.I was not following this pattern (my actions had the payload “mixed” on the first object level), so I had to adapt all my actions first, fix the tests, then migrate the reducer to RTK and make sure the tests kept passing.
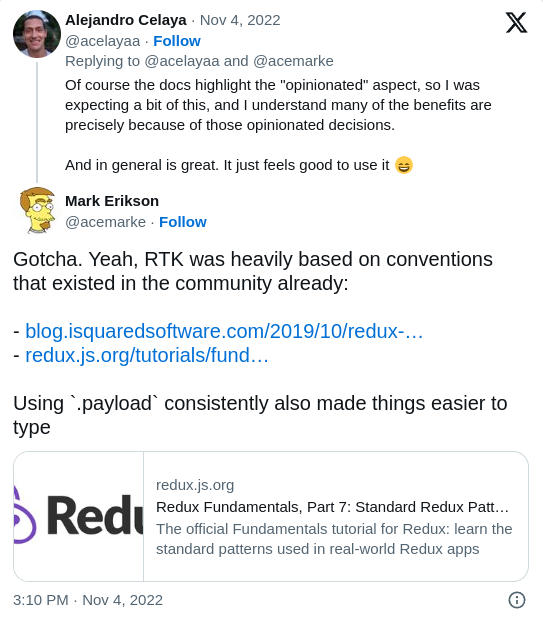
-
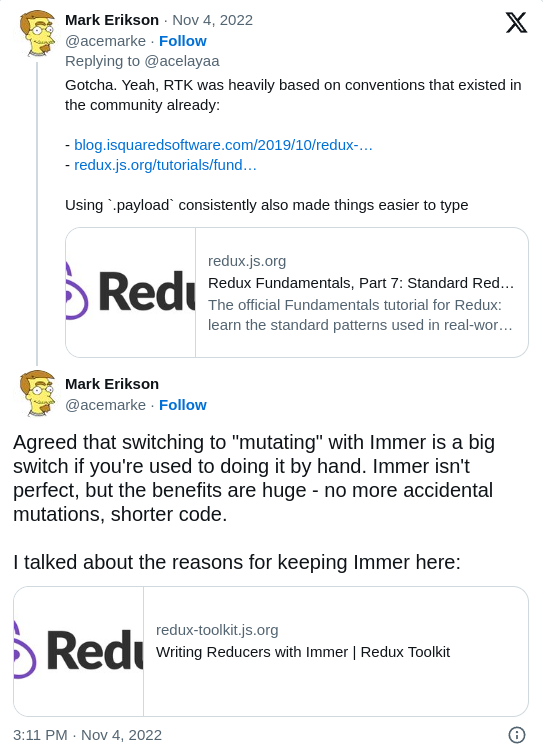
Immutability is no longer promoted in reducers. Instead, the library requires immer internally, and using proxies they automatically ensure immutability, even if you “mutate” the state.
This feels a bit counterintuitive at first, because redux always promoted an immutable approach, and the use of immer is not obvious.
However, they have good reasons to do it, and if your reducers return a state object, you can still use the immutable approach. It’s up to you.
-
Action creators resulting of
createAsyncThunkcan only have one argument.This is because the async thunk callback receives a second argument containing the
dispatchandgetStatefunctions, as well as a couple of other goodies, enforcing this convention to avoid human errors.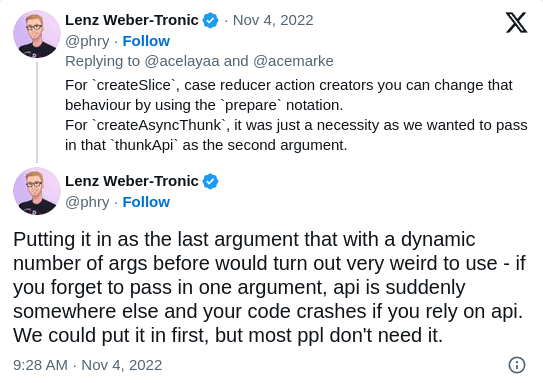
-
You cannot dispatch other actions after the callback passed to
createAsyncThunk, because it has to return the payload and RTK dispatches the action for you.However, this is probably something you usually should not be doing, and in my case, I resolved it with the listener middleware, listening for the second action in order to dispatch the second one.
Conclusion
My conclusion is that RTK is definitely worth it if you use redux.
It makes code simpler, more predictable and better typed. However, it still requires knowing how redux works internally and what are its patterns, in order to understand why the library exposes the helpers it exposes and why.
For existing redux projects, you can migrate progressively, addressing the challenges bit by bit and not all at once, which simplifies its adoption.
For new projects in which you want to use redux, I would recommend starting right away with RTK.